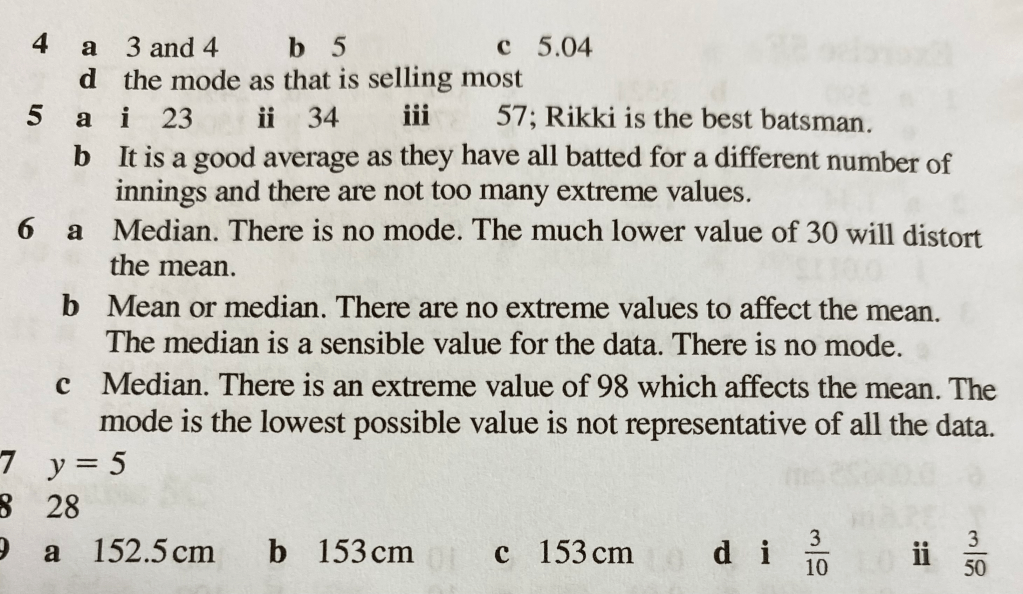When we want to summarise a dataset there are two numbers which are the most important single numbers to summarise them.
The first is the average, which tells us around what values the dataset is located.
The second is the dispersion, which indicates to us how widely spread the dataset it.
The most common measures of average, and the ones that we will study are the mode, the median and the (arithmetic) mean. The only measure of dispersion which we will study this year is the range.
Let’s look at how to calculate each of these four measures, for raw data and from a frequency table
Example
Below are the weekly wages in dollars of a random selection of employees at a company:

Below are the scores in a maths test of 20 students:

Exercise
Now that we’ve got the idea, let’s practice calculating averages in exercise 6G on pages 89 and 90 of our textbook:


Below are the answers:

Comparing averages
Which do you think is the best average? Why? What can you say in support of using each of the different averages? What can you say against using each of the different averages?
Exercise
Let’s complete exercise 6H on pages 90-91 of the textbook:



Below are the answers: